
RANSAC -algoritmi
RANSAC ( englanti ran dom sa mple c onsensus , saksaksi "ottelu satunnaisotannan kanssa") on näytteenotto uudelleen - algoritmi mallin arvioimiseksi mittaussarjassa, jossa on poikkeamia ja karkeita virheitä . Koska sen kestävyyttä vastaan poikkeavuuksien sitä käytetään pääasiassa arvioinnissa automaattisen mittauksia konenäön kenttään. Tässä RANSAC tukee - laskemalla poikkeamille mukautettua tietomäärää, niin sanottua konsensusjoukkoa - korvausmenetelmiä, kuten pienimmän neliösumman menetelmää , joka yleensä epäonnistuu suurella määrällä poikkeamia.
Martin A. Fischler ja Robert C. Bolles esittivät RANSACin virallisesti vuonna 1981 julkaisussa ACM Communications . Sisäinen esitys SRI Internationalissa , jonka parissa molemmat kirjoittajat työskentelivät, pidettiin maaliskuussa 1980. M-estimaattorit ovat vaihtoehto RANSACille . Verrattuna muihin estimaatteihin, kuten suurimman todennäköisyyden estimaattoreihin, nämä ovat vahvempia poikkeamia vastaan.
Johdanto ja periaate
Mittauksen tulos on usein datapisteitä, jotka edustavat fyysisiä arvoja, kuten painetta, etäisyyttä tai lämpötilaa, taloudellisia parametreja tai vastaavia. Näihin pisteisiin tulisi sijoittaa parametririippuvainen mallikäyrä, joka sopii mahdollisimman tarkasti. Käytettävissä on enemmän datapisteitä kuin on tarpeen parametrien määrittämiseksi; malli on siis ylimääritelty . Mitatut arvot voivat sisältää poikkeamia eli arvoja, jotka eivät sovi odotettuun mittaussarjaan . Koska mittaukset tehtiin enimmäkseen manuaalisesti digitaalitekniikan kehitykseen asti, kirurgin suorittama ohjaus tarkoitti, että poikkeavien osuus oli yleensä pieni. Tuolloin käytetyt kompensointialgoritmit , kuten pienimmän neliösumman menetelmä, soveltuvat hyvin tällaisten tietojoukkojen arviointiin, joilla on vähän poikkeamia: Heidän avullaan malli määritetään ensin koko datapisteestä ja sitten yritetään tehty havaitsemaan poikkeamat.

Kehittämällä digitaalitekniikan alusta 1980, perustekijät muuttunut. Uusien mahdollisuuksien vuoksi automaattisia mittausmenetelmiä käytettiin yhä enemmän, erityisesti tietokonenäköalalla . Tuloksena on usein suuri määrä arvoja, jotka sisältävät yleensä monia poikkeamia. Perinteiset menetelmät olettavat virheiden normaalijakauman eivätkä toisinaan anna järkevää tulosta, jos datapisteet sisältävät monia poikkeamia. Tämä näkyy vastakkaisessa kuvassa. Suora (malli) on sovitettava pisteisiin (mitattuihin arvoihin). Toisaalta 20 datapisteen yksittäisiä poikkeamia ei voida sulkea pois käyttämällä perinteisiä menetelmiä ennen suoran määrittämistä. Toisaalta sillä on asemastaan johtuen suhteettoman vahva vaikutus regressiolinjaan (ns. Vipuvaikutuspiste).
RANSAC -algoritmi noudattaa uutta iteratiivista lähestymistapaa. Kaikkien mitattujen arvojen tasaamisen sijasta käytetään vain niin monta satunnaisesti valittua arvoa kuin on tarpeen malliparametrien laskemiseksi (suoran tapauksessa tämä olisi kaksi pistettä). Aluksi oletetaan, että valitut arvot eivät ole poikkeavia. Tämä oletus tarkistetaan laskemalla ensin malli satunnaisesti valituista arvoista ja määrittämällä sitten kaikkien mitattujen arvojen (eli ei vain alun perin valittujen) etäisyys tähän malliin. Jos mitatun arvon ja mallin välinen etäisyys on pienempi kuin aiemmin määritetty kynnysarvo, tämä mitattu arvo ei ole bruttovirhe laskettuun malliin verrattuna. Joten hän tukee sitä. Mitä enemmän mitatut arvot tukevat mallia, sitä todennäköisemmin mallin laskennassa satunnaisesti valitut arvot eivät sisältäneet poikkeamia. Nämä kolme vaihetta - mittausarvojen satunnainen valinta, malliparametrien laskeminen ja tuen määrittäminen - toistetaan useita kertoja toisistaan riippumatta. Jokaisessa iteroinnissa tallennetaan mitatut arvot, jotka tukevat vastaavaa mallia. Tätä joukkoa kutsutaan konsensusjoukkoksi . Laajimmasta yhteisymmärryksestä , joka ideaalisesti ei enää sisällä poikkeamia, ratkaisu määritetään käyttämällä jotakin perinteistä säätömenetelmää.
Sovellukset
Kuten mainittiin, monet poikkeamat esiintyvät pääasiassa automaattisilla mittauksilla. Nämä suoritetaan usein tietokonenäön alalla , joten RANSAC on erityisen laajalle levinnyt täällä. Jotkut sovellukset on esitetty alla.

In kuvankäsittely , RANSAC käytetään määrittämään homologisia pisteitä kahden kameran kuvien. Kaksi kuvapistettä, jotka yksi objektipiste luo kahteen kuvaan, ovat homologisia. Homologisten pisteiden osoittamista kutsutaan vastaavuusongelmaksi. Automaattisen analyysin tulos sisältää yleensä suuren määrän vääriä tehtäviä. Kirjeenvaihtoanalyysin tuloksiin perustuvat menettelyt käyttävät RANSACia virheellisten määritysten sulkemiseen pois. Esimerkki tästä lähestymistavasta on panoraamakuvan luominen pienistä yksittäisistä kuvista ( ompeleminen ). Toinen on epipolaarisen geometrian laskeminen . Tämä on geometrian malli, joka näyttää saman objektin eri kamerakuvien väliset geometriset suhteet. Tässä RANSACia käytetään perusmatriisin määrittämiseen, joka kuvaa kuvien välistä geometrista suhdetta.
Vuonna DARPA Grand Challenge , kilpailu autonominen maa-ajoneuvoihin, RANSAC käytettiin määrittämään tienpinnan ja rekonstruoida ajoneuvon liikettä.
Algoritmia käytetään myös geometristen kappaleiden, kuten sylinterien tai vastaavien , mukauttamiseen meluisissa kolmiulotteisissa pistejoukoissa tai pistepilvien automaattiseen segmentointiin . Kaikkia pisteitä, jotka eivät kuulu samaan segmenttiin, käsitellään poikkeavina. Kun pistepilven hallitsevin kappale on arvioitu, kaikki tähän kappaleeseen kuuluvat pisteet poistetaan, jotta lisäkappaleet voidaan määrittää seuraavassa vaiheessa. Tämä prosessi toistetaan, kunnes kaikki pistejoukon kappaleet on löydetty.
Menettely ja parametrit
RANSACin edellytys on, että käytettävissä on enemmän datapisteitä kuin on tarpeen malliparametrien määrittämiseksi. Algoritmi koostuu seuraavista vaiheista:
- Valitse satunnaisesti datapisteistä niin monta pistettä kuin on tarpeen mallin parametrien laskemiseksi. Tämä tehdään olettaen, että tämä sarja on vapaa vieraista.
- Määritä malliparametrit valittujen pisteiden avulla.
- Määritä mitattujen arvojen osajoukko, jonka etäisyys mallikäyrästä on pienempi kuin tietty raja -arvo (tätä osajoukkoa kutsutaan konsensusjoukkoksi ). Jos se sisältää tietyn vähimmäismäärän arvoja, hyvä malli on todennäköisesti löydetty ja konsensusjoukko tallennetaan.
- Toista vaiheet 1-3 useita kertoja.
Useiden iterointien jälkeen valitaan se osajoukko, joka sisältää eniten pisteitä (jos sellainen on löydetty). Malliparametrit lasketaan jollakin tavallisista kompensointimenetelmistä vain tällä osajoukolla. Vaihtoehtoinen algoritmin muunnos lopettaa iteraatiot ennenaikaisesti, jos tarpeeksi pisteitä tukee mallia vaiheessa 3. Tätä vaihtoehtoa kutsutaan ennalta ehkäiseväksi - eli ennenaikaisesti päättyväksi - RANSACiksi. Tätä lähestymistapaa käytettäessä on oltava etukäteen tiedossa, kuinka suuri poikkeava osuus on, jotta voidaan arvioida, tukevatko mitatut arvot mallia riittävästi.
Algoritmi riippuu olennaisesti kolmesta parametrista:
- datapisteen suurin etäisyys mallista, johon asti pistettä ei pidetä vakavana virheenä;
- toistojen lukumäärä ja
- pienin koko konsensus asetettu , eli pienin määrä pisteitä sopusoinnussa mallin.
Datapisteen suurin etäisyys mallista
Tämä parametri on olennainen algoritmin menestyksen kannalta. Toisin kuin kaksi muuta parametria, se on määritettävä ( konsensusjoukkoa ei tarvitse tarkistaa , ja iterointien määrä voidaan valita lähes rajattomaksi). Jos arvo on liian suuri tai liian pieni, algoritmi voi epäonnistua. Tämä näkyy seuraavissa kolmessa kuvassa. Yksi iterointivaihe näytetään kussakin tapauksessa. Kaksi satunnaisesti valittua pistettä, joilla vihreä malliviiva laskettiin, on väriltään sininen. Virherajojen on esitetty mustia viivoja. Näiden viivojen sisällä on oltava piste, joka tukee malliviivaa. Jos valittu etäisyys on liian suuri, liian monta poikkeamaa ei tunnisteta, joten väärässä mallissa voi olla sama määrä poikkeamia kuin oikeassa mallissa (kuvat 1a ja 1b). Jos se on asetettu liian alhaiseksi, voi tapahtua, että malli, joka on laskettu poikkeamattomasta arvojoukosta, tukee liian vähän muita arvoja, jotka eivät ole poikkeamia (kuva 2).
- Ongelmia, jos virherajan valinta on liian suuri tai liian pieni

1a. Oikea ratkaisu, kaksi pistettä ovat poikkeamia.
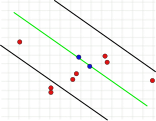
1b. Toiseksi väärä ratkaisu, jossa on sama määrä poikkeamia kuin kohdassa 1a.
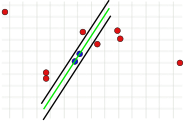
2. Virhe sidottu liian pieneksi.



Näistä ongelmista huolimatta tämä arvo on yleensä määritettävä empiirisesti . Virheraja voidaan laskea käyttämällä todennäköisyysjakauman lakeja vain, jos mitattujen arvojen keskihajonta tiedetään .
Toistojen lukumäärä
Toistojen määrä voidaan asettaa siten, että tietyllä todennäköisyydellä datapisteistä valitaan vähintään kerran poikkeamaton osajoukko. Jos mallin laskemiseen tarvittavien datapisteiden määrä ja poikkeamien suhteellinen osuus tiedossa, on todennäköistä, että vähintään yhtä poikkeamaa ei valita joka kerta toistojen tapauksessa




- ,

ja niin, että todennäköisyys, että vähintään yksi poikkeama valitaan joka kerta , on valittava riittävän suuri. Ole ainakin tarkempi


Toistoja tarvitaan. Luku riippuu siis vain poikkeavien osuudesta, mallitoiminnon parametrien lukumäärästä ja määritetystä todennäköisyydestä piirtää vähintään yksi poikkeamaton osajoukko. Se on riippumaton mitattujen arvojen kokonaismäärästä.
Seuraavassa taulukossa esitetään tarvittavien toistojen määrä riippuen poikkeamien osuudesta ja malliparametrien määrittämiseen tarvittavien pisteiden määrästä. Todennäköisyys valita vähintään yksi poikkeamaton osajoukko kaikista datapisteistä on 99%.
| esimerkki | Määrä pisteitä tarvitaan |
Poikkeava prosenttiosuus | ||||||
|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | ||
| Vain | 2 | 3 | 5 | 7 | 11 | 17 | 27 | 49 |
| taso | 3 | 4 | 7 | 11 | 19 | 35 | 70 | 169 |
| Perusmatriisi | 8 | 9 | 26 | 78 | 272 | 1177 | 7025 | 70188 |

Konsensus asetettu koko
Algoritmin yleisessä muunnelmassa tätä arvoa ei välttämättä tarvitse tietää, koska jos uskottavuustarkistus jätetään pois, suurinta konsensusjoukkoa voidaan yksinkertaisesti käyttää jatkokurssilla. Tämä tieto on kuitenkin välttämätöntä ennenaikaisesti päättyvälle variantille. Tässä tapauksessa konsensusjoukon vähimmäiskoko määritetään yleensä analyyttisesti tai kokeellisesti. Hyvä arvio on mitattujen arvojen kokonaismäärä vähennettynä tiedoissa epäiltyjen poikkeamien osuudella . Vähimmäiskoko on sama ja datapisteiden . Esimerkiksi 12 datapistettä ja 20% poikkeavuuksia käytettäessä minimikoko on noin 10.

Mukautuva parametrien määrittäminen
Poikkeavien osuudet datapisteiden kokonaismäärästä ovat usein tuntemattomia. Siksi ei ole mahdollista määrittää tarvittavaa toistojen määrää ja konsensusjoukon vähimmäiskokoa . Tässä tapauksessa algoritmi alustetaan pahimmassa tapauksessa olettaen, että esimerkiksi 50%: n poikkeamaosuus on, ja iteraatioiden lukumäärä ja konsensusjoukon koko lasketaan vastaavasti. Jokaisen iteroinnin jälkeen näitä kahta arvoa säädetään, jos havaitaan suurempi johdonmukainen joukko. Jos esimerkiksi algoritmi aloitetaan poikkeavalla osuudella 50% ja laskettu konsensusjoukko sisältää 80% kaikista datapisteistä, tuloksena on 20%: n ulkopuolisen osuuden parempi arvo. Toistojen lukumäärä ja konsensussarjan tarvittava koko lasketaan sitten uudelleen.
esimerkki
Tason pisteisiin on asennettava suora viiva. Pisteet näkyvät ensimmäisessä kuvassa. Toisessa kuvassa näkyy eri juoksujen tulos. Punaiset pisteet tukevat suoraa viivaa. Pisteet, joiden etäisyys suorasta on suurempi kuin virheraja, on väriltään sininen. Kolmas kuva esittää ratkaisun, joka on löydetty 1000 iterointivaiheen jälkeen.
- RANSAC suoran mukauttamiseksi datapisteisiin
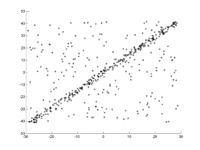
1. Alkuperäinen tietojoukko.
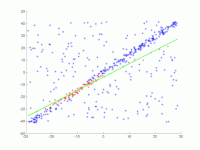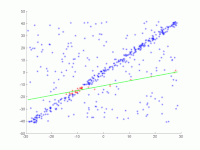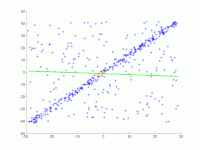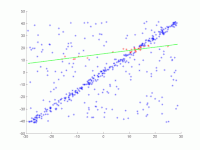
2. Useiden iterointien animaatio.
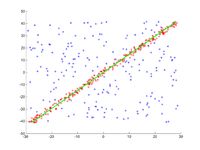
3. Tulos 1000 iteraation jälkeen.



Edistyksiä
RANSACiin on joitakin laajennuksia, joista kaksi tärkeää on esitetty tässä.
LO-RANSAC

Kokeet ovat osoittaneet, että useimmiten tarvitaan enemmän iterointivaiheita kuin teoreettisesti riittävä määrä: Jos malli lasketaan poikkeamattomasta pistejoukosta, kaikkien muiden arvojen, jotka eivät ole poikkeavia, ei tarvitse tukea tätä mallia. Ongelma on kuvattu vastakkaisessa kuvassa. Vaikka suora laskettiin käyttämällä kahta virheetöntä arvoa (mustia pisteitä), jotkut muut ilmeisesti oikeat pisteet luokitellaan poikkeaviksi (siniset tähdet) kuvan oikeassa yläkulmassa.
Tästä syystä alkuperäistä algoritmia LO-RANSACille (paikallisesti optimoitu RANSAC) laajennetaan vaiheessa 3. Ensinnäkin, kuten tavallista, määritetään niiden pisteiden osajoukko, jotka eivät ole poikkeavia. Malli määritetään sitten uudelleen käyttämällä tätä joukkoa ja käyttämällä mitä tahansa kompensointimenetelmää, kuten pienimmän neliösumman menetelmää. Lopuksi lasketaan osajoukko, jonka etäisyys tähän optimoituun malliin on pienempi kuin virheraja. Vain tämä parannettu osajoukko tallennetaan konsensusjoukkoksi .
MSAC
RANSAC valitsee mallin, jota useimmat mittausarvot tukevat. Tämä vastaa summan minimointia, jossa kaikki virheettömät arvot syötetään 0: lla ja kaikki poikkeavat arvot vakioarvolla:


Laskettu malli voi olla hyvin epätarkka, jos virheraja asetetaan liian korkeaksi - mitä korkeampi se on, sitä useammalla ratkaisulla on samat arvot . Äärimmäisessä tapauksessa kaikki mitattujen arvojen virheet ovat pienempiä kuin virheraja, joten se on aina 0. Tämä tarkoittaa, että poikkeamia ei voida tunnistaa ja RANSAC antaa huonon arvion.
MSAC ( M -Estimator SA mple C onsensus) on RANSACin laajennus, joka käyttää muunnettua tavoitefunktiota minimoimiseksi:

Tämän toiminnon avulla poikkeavat saavat edelleen tietyn "rangaistuksen", joka on suurempi kuin virheraja. Virherajan alapuolella olevat arvot sisältyvät virheen kokonaismäärään 0: n sijasta. Tämä poistaa mainitun ongelman, koska piste vaikuttaa vähemmän kokonaismäärään, sitä paremmin se sopii malliin.
Yksilöllisiä todisteita
- ^ Robert C.Bolles: SRI : n kotisivu . ( verkossa [käytetty 11. maaliskuuta 2008]).
- ↑ Martin A.Fischler: SRI : n kotisivu . ( verkossa [käytetty 11. maaliskuuta 2008]).
- ↑ Martin A.Fischler ja Robert C.Bolles: Satunnainen otos konsensuksesta: paradigma mallien sovittamiseen sovelluksiin kuva -analyysiin ja automaattiseen kartografiaan . Maaliskuu 1980 ( verkossa [PDF; 301 kB ; Käytetty 13. syyskuuta 2007]).
- ↑ Dag Ewering: Mallipohjainen seuranta käyttäen viiva- ja pistekorrelaatioita . Syyskuu 2006 ( verkossa [PDF; 9.5 MB ; Käytetty 2. elokuuta 2007]).
- ^ Martin A. Fischler ja Robert C. Bolles: RANSAC: An Historical Perspective . 6. kesäkuuta 2006 ( verkossa [PPT; 2.8 MB ; Käytetty 11. maaliskuuta 2008]).
- ↑ Christian Beder ja Wolfgang Förstner : Sylinterien suora määrittäminen 3D -pisteistä ilman pintanormaaleja . 2006 ( uni-bonn.de [PDF; katsottu 25. elokuuta 2016]).
- ^ Ondřej Chum, Jiři Matas ja Štěpàn Obdržàlek: RANSACin parantaminen yleisellä mallin optimoinnilla . 2004 ( verkossa [PDF; käytetty 7. elokuuta 2007]).
- ↑ PHS Torr ja A. Zisserman: MLESAC: Uusi vankka estimaattori, jota käytetään kuvan geometrian arvioimiseen . 1996 ( verkossa [PDF; 855 kB ; Käytetty 7. elokuuta 2007]).
kirjallisuus
- Martin A.Fischler ja Robert C.Bolles: Satunnainen otos konsensuksesta: paradigma mallien sovittamiseen sovelluksilla kuva -analyysiin ja automaattiseen kartografiaan. (PDF; 1,2 Mt) (Ei enää saatavilla verkossa.) 1981, arkistoitu alkuperäisestä 5. huhtikuuta 2019 ; käytetty 14. lokakuuta 2019 .
- Eri kirjoittajia: 25 vuotta RANSACia, Workshop yhdessä CVPR 2006: n kanssa. 2006, käytetty 11. maaliskuuta 2008 .
- Peter Kovesi: RANSAC - Sovittaa mallin tukevasti dataan RANSAC -algoritmin avulla (Matlab -toteutus). 2007, käytetty 11. maaliskuuta 2008 .
- Volker Rodehorst: Fotogrammetrinen 3D-rekonstruktio lähietäisyydeltä automaattisen kalibroinnin ja projektiivisen geometrian avulla . wvb Wissenschaftlicher Verlag Berlin, 2004, ISBN 978-3-936846-83-6 (yliopiston julkaisu ja väitöskirja, TU Berlin 2004).
- Richard Hartley, Andrew Zisserman: Usean näkymän geometria tietokonevisiossa . 2. painos. Cambridge University Press, Cambridge, UK 2004, ISBN 978-0-521-54051-3 (englanti).
- Tilo Strutz: Tietojen sovittaminen ja epävarmuus (Käytännöllinen johdanto painotettuihin pienimpiin neliöihin ja sen jälkeen) . 2. painos. Springer Vieweg, 2016, ISBN 978-3-658-11455-8 (englanti).